| New Info | ������� | ��&Pub News | ������� � ��������� | ������ � ��������� | ���������� | ������� ����� | ������ � ������ |
 |
|
| Acompnews--------------------------------------- ������� �������� � ������� | |
. 5224 - 5224.
| T-Bank Al Re�search |
| 2 �������� 2024 �. � 14:11 |
| AI Research - ���������� ������ �������� ������ �������������� ���������� � ������� ������� ������ �� ����������� ������������ �������������� ���������� (��) T-Bank AI Research ����������� ��������� ReBased ��� ���������� ��������� ������� �������. ����� ���������� ��������� ������� �� ������������� �� � ��������� ������� ����������� ��� ������ � ��������. � ����������� ��� �������� ���� ��������� ��������� ������ � �������, ��� ��� ������ �� �������������� ������������ �������� ������� �� ���������������� ���������. ����� ����, �������� ����������� ������� � ������� �����������, ��������� � �������� �������� ��������� �������, ������� ���������� ���������� �������� �� ����������� ����� � ��������� �������� ���������� �����. ����������� ������������ ���� �������� ������� �������� ����������� � ������������ �� 63-� ������������� ��������� ������������� �� ������������� ����������� (ACL), ������� �������� � ��������, �������, � 11 �� 16 ������� 2024 ����. ��� ������� �������� ������������� � ������� ��������� �������������� ������ � ����. �������� ������ ���������� ���� �� ����� ��������� �������������� �������������� ��������������� ����������� � ����, ���������������� �������������� ����������� � ����������� ������� � �������. ����� ��� ��������� ������ � ���� ����������� ������� �� ���������. ���� ��������� � ������ ��������� ����� ����� ����������� ��������� �������, ���������� Re�Based. ����������� � �������� �������� � ��� ����� ���� ��� ���������, �� ������� �������� ���������� ����. ��� �����������, ����� ���� ����� ����� ������������� (��������, �����������, ������������ ��� ������������) � ��� ��� ���� ����� ��������� ����� �����. ����� ������, ��� ��� ������ ����, ��� ���� ���� ������, ������� � �� ����������. ������ ������������ ����������� ���������� ��������� ������ ������ ������������� ������, �������� ������������ ����������� ��� �������� �����. ������ ����������� ����������� ����� ��� �������������� � ��������� ������ ������. ����� ����������������� ��������� ������ �������� �� ����������� ������������, ��������������� � 2017 ���� ���������������� �� Google. ��� ������ ���������������� ���� ��� ������� ������������ �����, �� ��� ��� ��������� ����� �������� ���������� ��������, ������� ������ ������������ � ���������� ������. ��� �������� ������������� ���������� ���������� ����� ���������������� �����������. �������� ��������� ������������ ������������� � ��������� SSM-������ (State Space Mod�el, ������ ������������� ����������) Mam�ba, �� ��� �������� �� ����������� ������������� ��������, ������� ���������� ��-�������� ��������������� � ����� ������� ��� ������������� ���������� ��������. � ������ Based, ��������������� �������� ���������� � ������� 2023 ����, ������� ������������ ��������� ����������� ������������� ��������, ����������� T-Bank AI Re�search ���������� �������������� �������������� �������� ��-�� �������������� ��������� ���������. ������� ������ ����������� Base, ������ �� T-Bank AI Re�search �������������� �������� ���������� ����������� �� ������, ������� ����� ��������� ���������, ������� �������� �� ������������ ����� ������������� ����� �������� ������. ��� ���������� ��������� ������� ��� ��������� � �������� ����� ������� ������. ������ ����� ��������� �������� ���������� ��������� �����������, ��� ������� � ���������� �������������������, ���������� �������� ������ � ���������� �������� � ���������� ������������� ��������. � ������� ��������� ������������� � ������ � ����� ����������� ����� ������ �� 10%. Re�Based �������� ������� �������� �� �������������� ��������������� ����������� ��� ������������������� �����, ������� ����� ����������� ������� ���������� � ������� ����� �� �������������. ��������, � �������� ����� ������� ����� ���������� ������������� ������� �� ������ ��������� � ���������. ����� �����������, ������������� ��������, ���������� ���������� �������� �������� ������� � �������������. ������, � ������ ������� ����� Re�Based, ����� ������������ ������ � ����� ������� ������������� � �������� ����������� ��� ������ ��������. ������ ��������� ������������� �� �������� MQAR (Multi-Query As�so�cia�tive Re�call), ������� ���������� ���������� ����������� ������ � ������������������ ��������, � ������� � �������������� ����������� (����������� �� ����������� ��� ���������), ��������: ���� �������� � ��� ���. 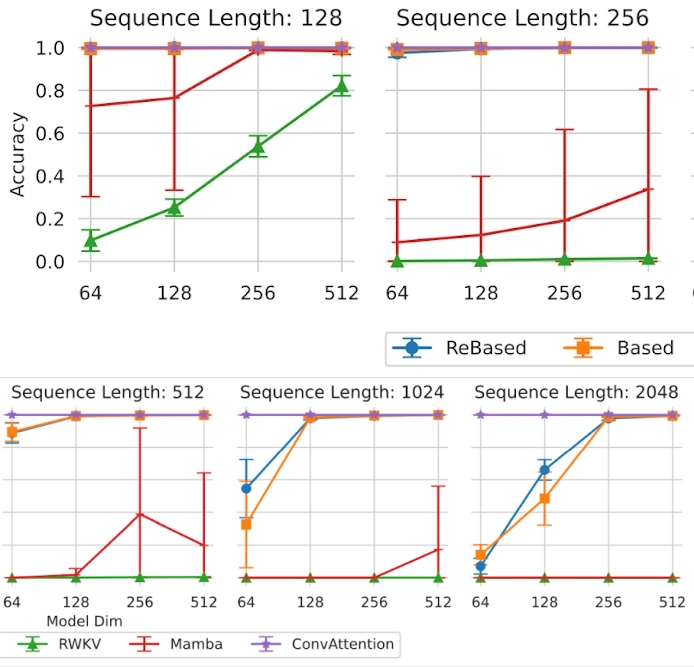 ���. 1. ����������� �� ������ ������� MQAR, ��������������� ��� ��������� ������������ ������������� �������� ����������� Aro�ra � ��. (2024). Re�Based ����������� ��� ������������ ������ � ������������ ������������� �������� ������� �������, ������������� ��������� �������������� ������ � T-Bbank AI Re�search: ���������������, ��� ������������ � �������� ����� ������ ������ �������������� �� ���������� ���������� ������������ �� ��� �� ����, �� � ������ �������� � �������. ������ ��� ���� �� �������� ����������� �������� ������������ � NLP �� ����� ����: ������������ �������� ����������, �� �������� ������ �������� �� �� ��������. � ��, � ������ �� ���������� ���������� ������� ������������ ����������. �� ����� �� ����� � �������� ����������� � ���� ����������� ����������� � �������� ������� ������ �������. � ����������� �������� ������ ��� ���� ����� ���������������� � ���������� � �������������� � �������� ��������� ����� ��������� ����������. ����� ����������� �������� � ���� � ��������, � �������� �������� ����������� �����. ��������� �������� ������ � ����������� �������������� �������� � ������ Lin�ear Trans�formers with Learn�able Kernel Func�tions are Bet�ter In-Con�text Mod�els. �������� ��� � ��������������� ��������� ����� ����� �� GitHub. T-Bank Al Re�search � ��� ���� �� �������� ���������� �����������, ������� ���������� �������������������� ���������� ��������������� �� ���� �������. ����������� ������ � ������ ������� ��������������� ����������� �-������. ������ �� T-Bank Al Re�search ��������� �������� ������������� ������� ��: ��������� �������������� ������ (NLP), ������������� ������ (CV) � ������������������ ������� (Rec�Sys). �� ������������ �������������� ��� ����� �������� ������ ��� �������� ������������ ������������� �������� �������������: NeurIPS, ICML, ACL, CVPR � ������. �� ��� ���� ������������� �������� ����� 20 ������ ���� ������� �� ���������� ������������� � �������� � ������� ��. �������� ������ T-Bank Al Re�search ���������� �������� �� ������������� ������ � ����������, � ����� ������������������� ������� Google �� �������� ��������������� ����������� Google Deep�Mind. �������� �������� ������������������ ����������� T-Bank Lab � ���� � Omut AI � ������������� ������������ � �������� ����������� ���������� ��������� �������� ���������. |
> |
||